Scribo, Ergo Sum: Can You Trust What You See? Human and AI Detection of Synthetic Legal Evidence
Premier prix – Concours de blogue 2026

Jinzhe Tan est doctorant en Intelligence Artificielle et Droit à la Faculté de droit de l’Université de Montréal, sous la direction du professeur Karim Benyekhlef. Ses recherches portent sur l’utilisation de l’intelligence artificielle pour améliorer l’accès à la justice, faciliter le règlement des litiges en ligne et renforcer l’équité dans la prise de décision judiciaire.
Can You Trust What You See? Human and AI Detection of Synthetic Legal Evidence
Introduction
We use digital images as evidence in everyday disputes and legal proceedings. From a photo of a damaged package submitted to an e-commerce platform, an insurance claim supported by images of a car scratch, or documentary evidence filed in court, visual evidence supports countless legal and quasi-legal decisions every day. The use of visual evidence rests on the assumption that photos constitute a faithful record of reality – or, as the proverb puts it: “seeing is believing.”
The evolution of generative artificial intelligence has challenged the aforementioned premise. Multimodal large language models (MLLMs), models that can understand and generate images, audios, videos and more, enable virtually anyone to fabricate highly realistic synthetic images in seconds. Unlike earlier “deepfake” techniques, which provides limited access and primarily targeted identity-related manipulations such as face swapping, today’s generators can generate almost anything. MLLMs can create visual evidence that never existed or edit real images to change their evidentiary meaning—all through simple prompts. The pace of advancement for these models is jaw-dropping, with their rendering of lighting, material properties, and texture continuity improves, synthetic images can remain visually coherent with surrounding scene while precisely pinpoint the fact in dispute.
The legal consequences are no longer hypothetical. In one of the earliest documented judicial instances, a California court rejected and sanctioned the submission of AI-generated video evidence that purported to depict a real witness. In China, reports have emerged of consumers allegedly submitting AI-altered images of spoiled or damaged goods to obtain fraudulent refunds, with platforms acknowledging their inability to determine whether the images had been AI-generated. These cases make us begin to doubt—can we still trust what we see?
To address this question, we conducted an empirical study evaluating the ability of both human participants and state-of-the-art MLLMs to distinguish authentic legal evidence images from their AI-generated counterparts.
Experimental Design
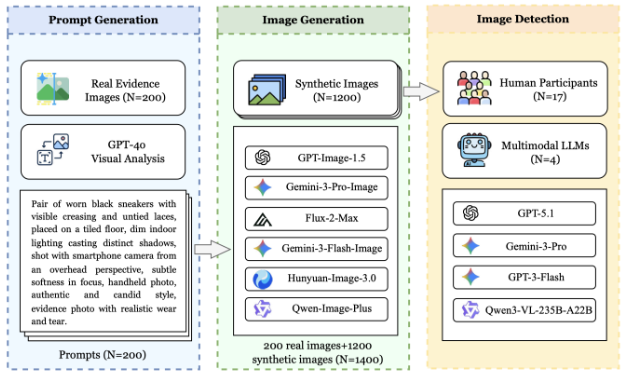
Figure 1: Overview of the experimental design.
Our research is based on a carefully constructed paired dataset. We first collected 200 real-world evidence images covering ten common categories in civil disputes, including product defects, vehicle damage, food spoilage, electronic product damage, delivery scenarios, receipts, and more. We considered the authenticity of these images as everyday evidence when manually selecting them. Specifically, the selected images were not studio shots with perfect lighting and angles, but rather images taken under varying conditions, with different equipment and camera quality (from the latest high-end smartphones to older devices), and exhibiting some natural compositional flaws (e.g., motion blur or poor composition).
Based on these 200 images, we generated 1,200 synthetic images, with six synthetic images corresponding to each real images, using six leading text-to-image models:
- GPT Image 1.5 by OpenAI
- Gemini 3 Pro Image by Google
- Flux 2 Max by Black Forest Labs
- Gemini 2.5 Flash Image by Google
- Hunyuan Image 3.0 by Tencent
- Qwen Image Plus by Alibaba
Each authentic images wase recreated using a standardized pipeline by these six modesl. First, GPT-4o analyzed the original image and produced a detailed reconstruction prompt. We then sent this prompt to each generator, with no manual editing or post processing applied.
Using datasets created above, we conducted two parallel studies.
Study 1 involved human participants. Seventeen participants conducted the experiment using a web platform we customized for this study. Each participant viewed 20 images, including 10 real images and 10 synthetic images. For each image, participants were required to judge it as true, false, or uncertain, provide a confidence rating, and select up to three reason labels.
Study 2 evaluated vision language models. We sent all 1,400 images to four advanced visual language models: GPT-5.1, Gemini-3-Pro, GPT-3-Flash, Qwen3-VL-235B-A22B. All models were run under the same response conditions as in Study 1. This design allowed us to directly compare the performance of humans and vision language models.
Key findings
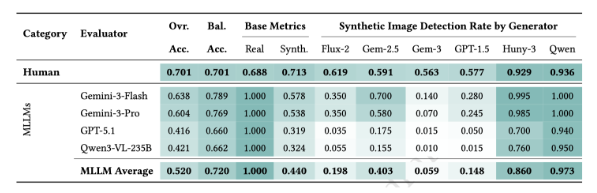
Figure 2: Performance comparison of humans and vision language models across authentic and synthetic images.
Human Performance. After excluding uncertain responses (10.6%), human participants achieved an overall accuracy of 70.1%. While this is higher than random guessing, it remains insufficient for such high-stakes legal decisions regarding evidence adoption. Participants identified 71.25% of synthetic images and 68.75% of real images, indicating a bidirectional confusion between real and synthetic images. Confidence ratings are relevant; accuracy reached 90.7% with the highest confidence level, dropping to 47.6% with lower confidence levels.
AI Performance. AI performance was more uneven compared to human participants. All four evaluated models identified every real image with 100% accuracy; however, they averaged 44% of synthetic images. This suggests a strong tendency for these models to avoid misidentifying real images as synthetic, even if this choice may reduce overall performance. This cautious approach may stem from limitations imposed by the model developers, but in evidence verification, the resulting oversight of forged images can have serious consequences.
Differences between image generators. The performance of different image generators varies significantly. Images generated by Qwen Image Plus and Hunyuan Image 3.0 were identified as synthetic images by humans and visual language models in over 90% of cases. In contrast, images generated by Gemini 3 Pro were much harder to identify. Humans identified them as synthetic images with an accuracy rate of only 56.3%, while visual language models achieved an even lower rate of 5.9%. The difference between the most easily identifiable and the most difficult-to-identify image generators was as high as 37 percentage points. This indicates that the choice of image generation tool is the most important factor affecting whether fabricated evidence can be detected.
Implications for Legal Practice
First, photographic evidence can no longer enjoy an unquestionable presumption of authenticity. Our 70.1% accuracy rate was achieved with human participants explicitly informed that certain images might be generated by AI, without such prior notification, real-world evaluators would likely perform even worse. Given the growing academic concern about the declining cognitive trust in visual evidence, courts and platforms that have historically accepted photographic evidence with minimal verification may need to reconsider this approach.
Second, vision language model is currently unsuitable as a reliable independent verification tool. The conservative tendencies of machine learning models mean that “real” classifications should never be considered guarantees of authenticity.
Third, the complementary failure modes of human and vision language models suggest the necessity of hybrid verification systems. A tiered framework could use vision language modes as an initial screening layer, then send AI-reviewed images to trained human reviewers who focus on subtle artifacts that escape automate detections.
Conclusion
The arms race between generation and detection technologies shows no signs of slowing down. Our findings represent a snapshot of capabilities in early 2026, and by the time these discoveries are widely disseminated, a new generation of more realistic models will likely have emerged. The impartiality of legal proceedings fundamentally depends on the reliability of evidence, and visual documents have long enjoyed a special status of trust. Our results suggest that this trust is now under threat, but also demonstrate that humans still possess meaningful, albeit imperfect, detection capabilities that should inform the design of authentication systems.
Ce contenu a été mis à jour le 14 avril 2026 à 14 h 50 min.